
面试必问:MySQL与Redis数据一致性如何保证?

背景
不知道大家有没有发现,如今的面试,不管你是面试初级、中级还是高级,高并发场景业务处理永远都绕不过去,正所谓面试造火箭,工作拧螺丝,博主深有体会。今天我们就来谈谈并发场景中经常被问及的一个问题:mysql和redis数据一致性问题。
我们知道,数据库大多数情况下都是用户并发访问最薄弱的环节,所以,智慧的人们就想到为什么不做一个缓存操作,让请求先访问到缓存,而不是直接访问的数据库,因此,redis出现了,但是存在一个致命问题,如果只是读取数据问题不大,但是如果涉及到更新数据,就会有一个时间差,数据库更新,缓存还没来得及更新的情况,因为,mysql和redis数据一致性问题就出现了。
大纲
本文将从下图所涉及的几个方面进行探讨
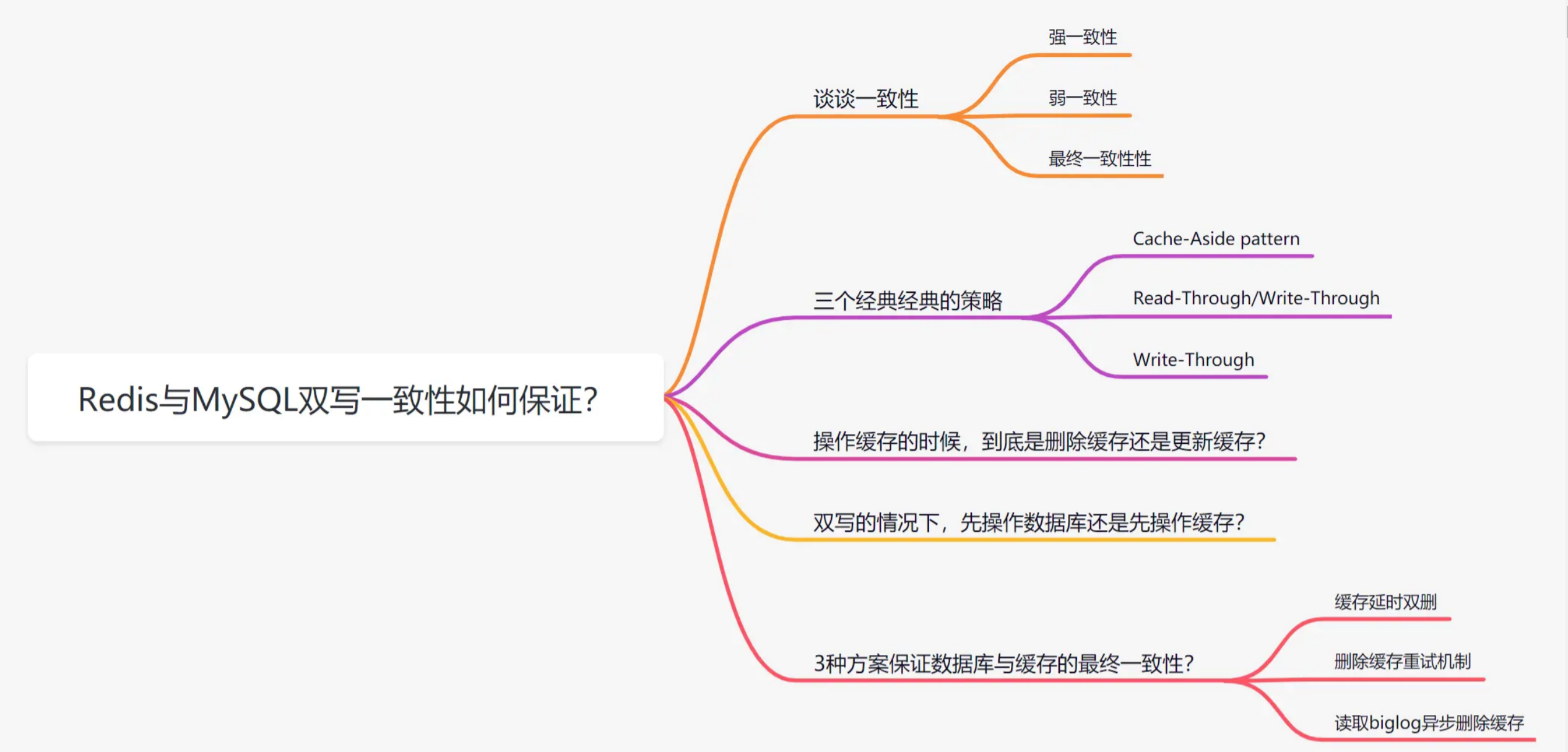
谈谈一致性
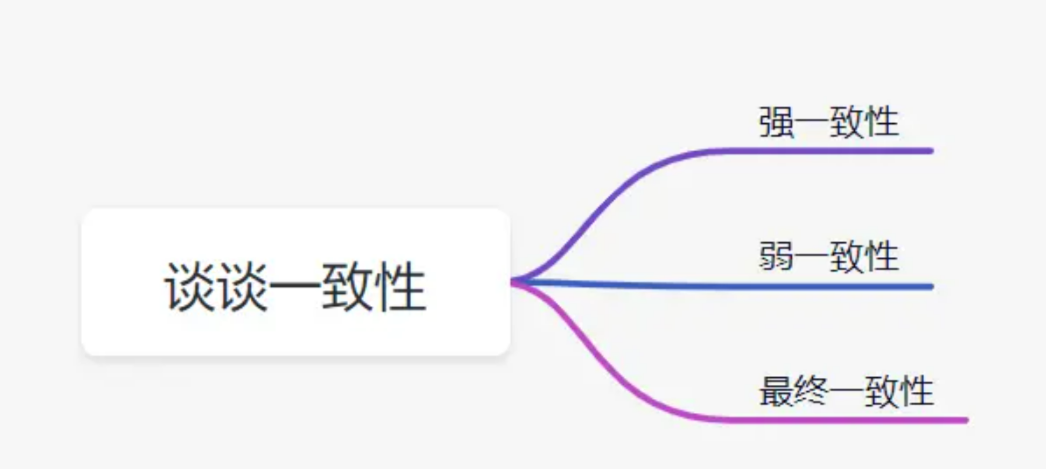
一致性简单的说就是数据保持一致,在分布式系统中,可以理解为多个节点中拿到的数据值是一样的,一致性又分为一下三种:
强一致性:当更新操作完成之后,在任何时刻所有的用户或者进程查询到的都是最近一次成功更新的数据。强一致性是程度最高一致性要求,也是最难实现的。关系型数据库更新操作就是这个案例。
弱一致性:当数据更新后,后续对该数据的读取操作可能得到更新后的值,也可能是更改前的值。
最终一致性:在某一时刻用户或者进程查询到的数据可能都不同,但是最终成功更新的数据都会被所有用户或者进程查询到。简单理解为,就是在一段时间后,数据会最终达到一致状态。
三个经典的缓存模式
缓存可以提升性能、缓解数据库压力,但是使用缓存也会导致数据不一致性的问题。一般我们是如何使用缓存呢?有三种经典的缓存模式:
Cache-Aside Pattern
Read-Through/Write through
Write behind
Cache-Aside Pattern
Cache-Aside Pattern,即旁路缓存模式,它的提出是为了尽可能地解决缓存与数据库的数据不一致问题。
Cache-Aside读流程
Cache-Aside Pattern的读请求流程如下:

读的时候,先读缓存,缓存命中的话,直接返回数据
缓存没有命中的话,就去读数据库,从数据库取出数据,放入缓存后,同时返回响应。
Cache-Aside 写流程
Cache-Aside Pattern的写请求流程如下:

更新的时候,先更新数据库,然后再删除缓存。
Read-Through/Write-Through(读写穿透)
Read/Write Through模式中,服务端把缓存作为主要数据存储。应用程序跟数据库缓存交互,都是通过抽象缓存层完成的。
Read-Through
Read-Through的简要流程如下
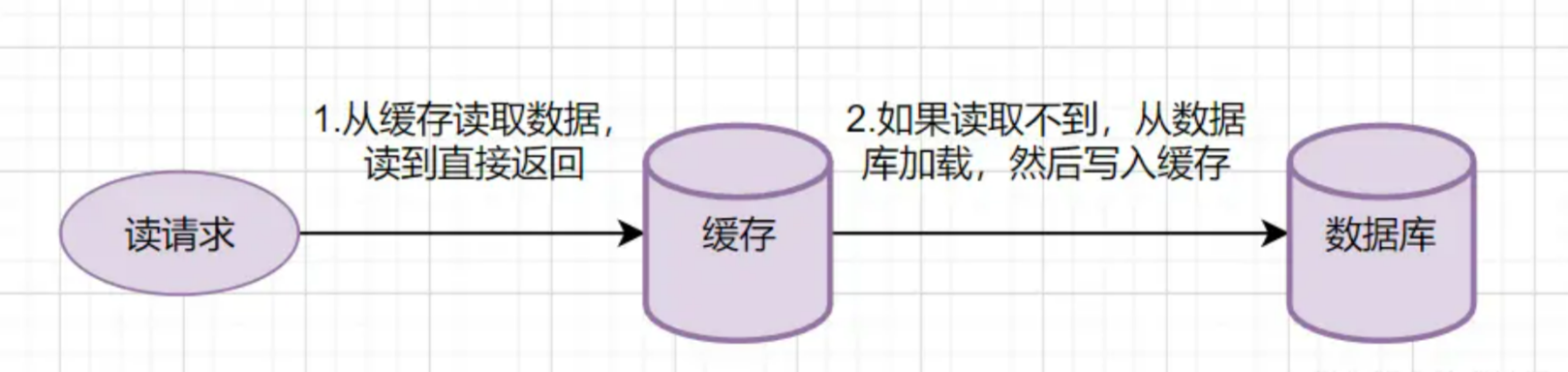
从缓存读取数据,读到直接返回
如果读取不到的话,从数据库加载,写入缓存后,再返回响应。
这个简要流程是不是跟Cache-Aside很像呢?其实Read-Through就是多了一层Cache-Provider,流程如下:
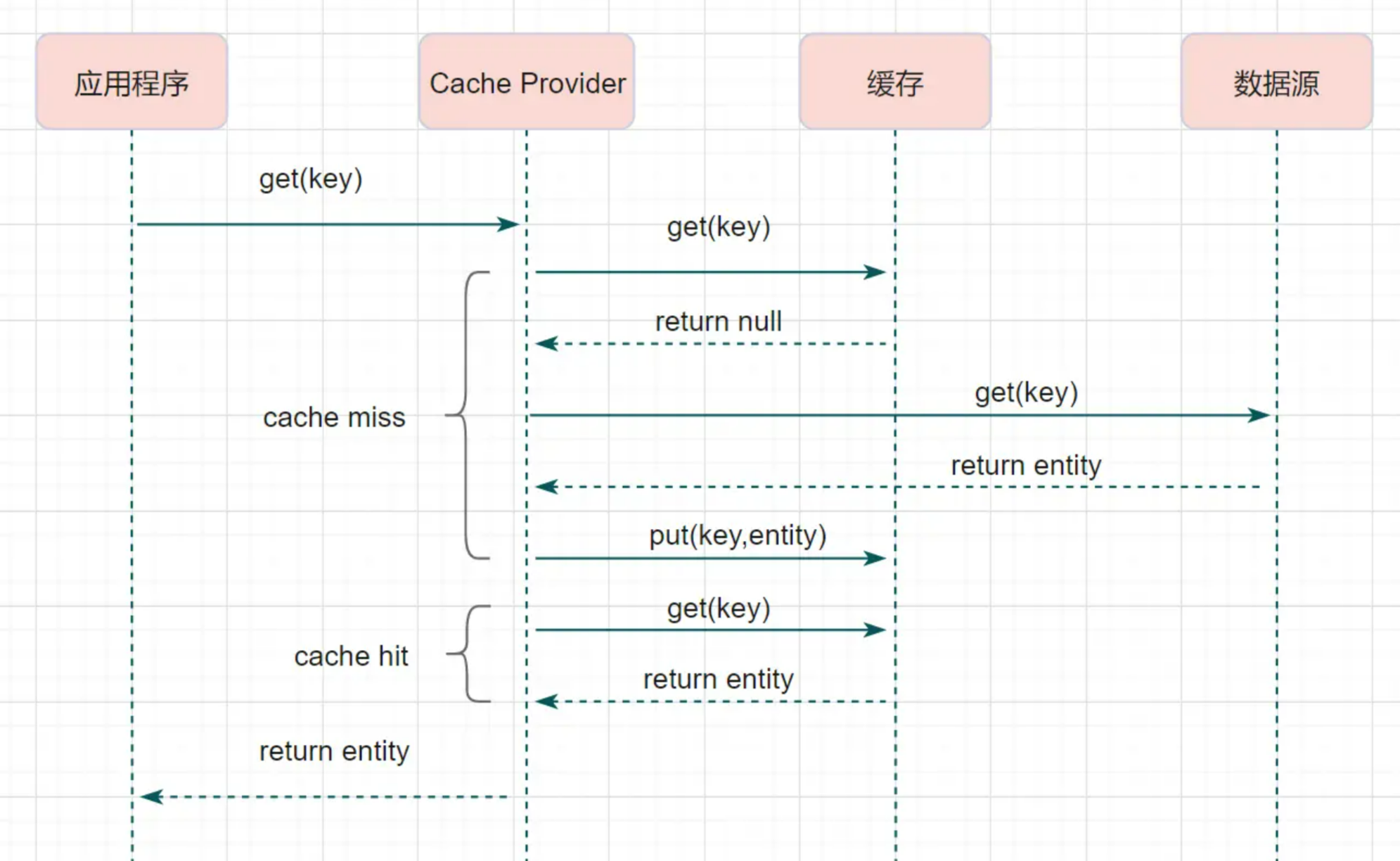
Read-Through实际只是在Cache-Aside之上进行了一层封装,它会让程序代码变得更简洁,同时也减少数据源上的负载。
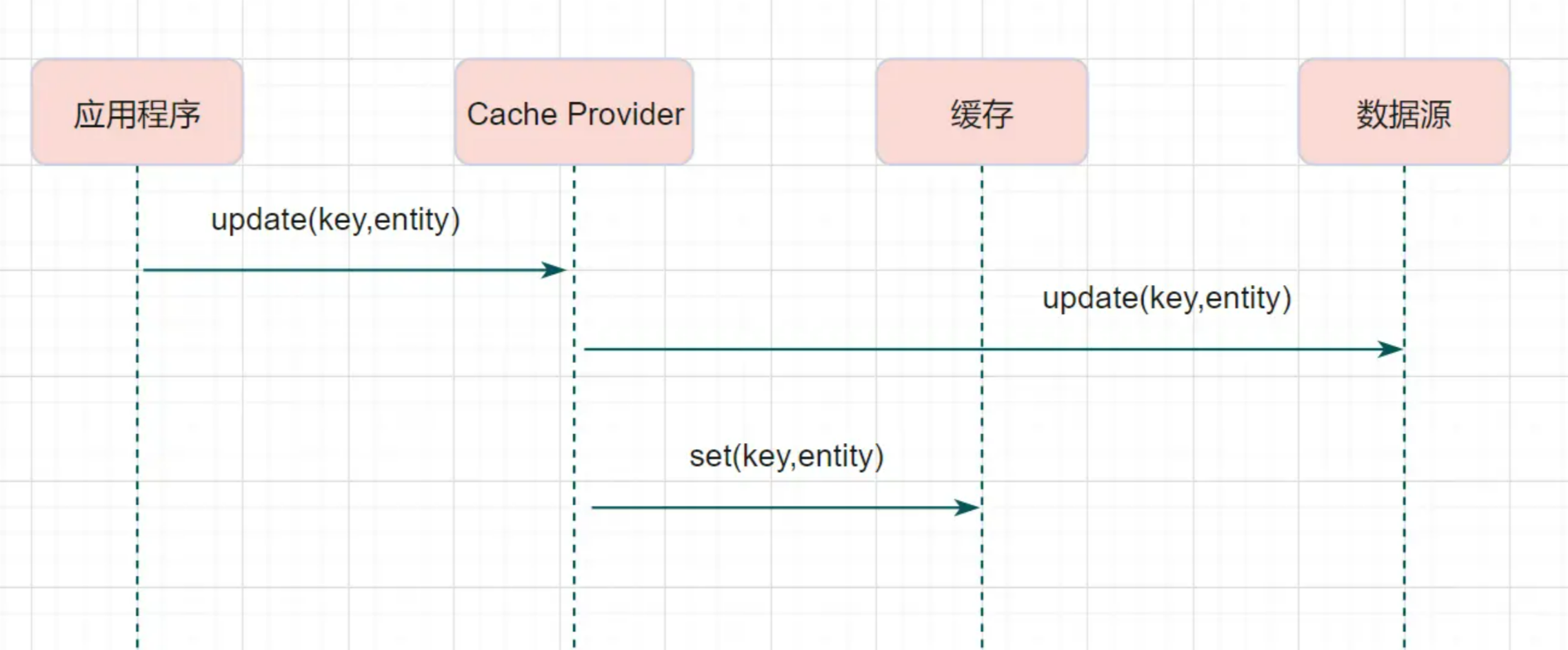
Write-Through
Write-Through模式下,当发生写请求时,也是由缓存抽象层完成数据源和缓存数据的更新,流程如下:
Write behind (异步缓存写入)
Write behind跟Read-Through/Write-Through有相似的地方,都是由Cache Provider来负责缓存和数据库的读写。它两又有个很大的不同:Read/Write Through是同步更新缓存和数据的,Write Behind则是只更新缓存,不直接更新数据库,通过批量异步的方式来更新数据库。
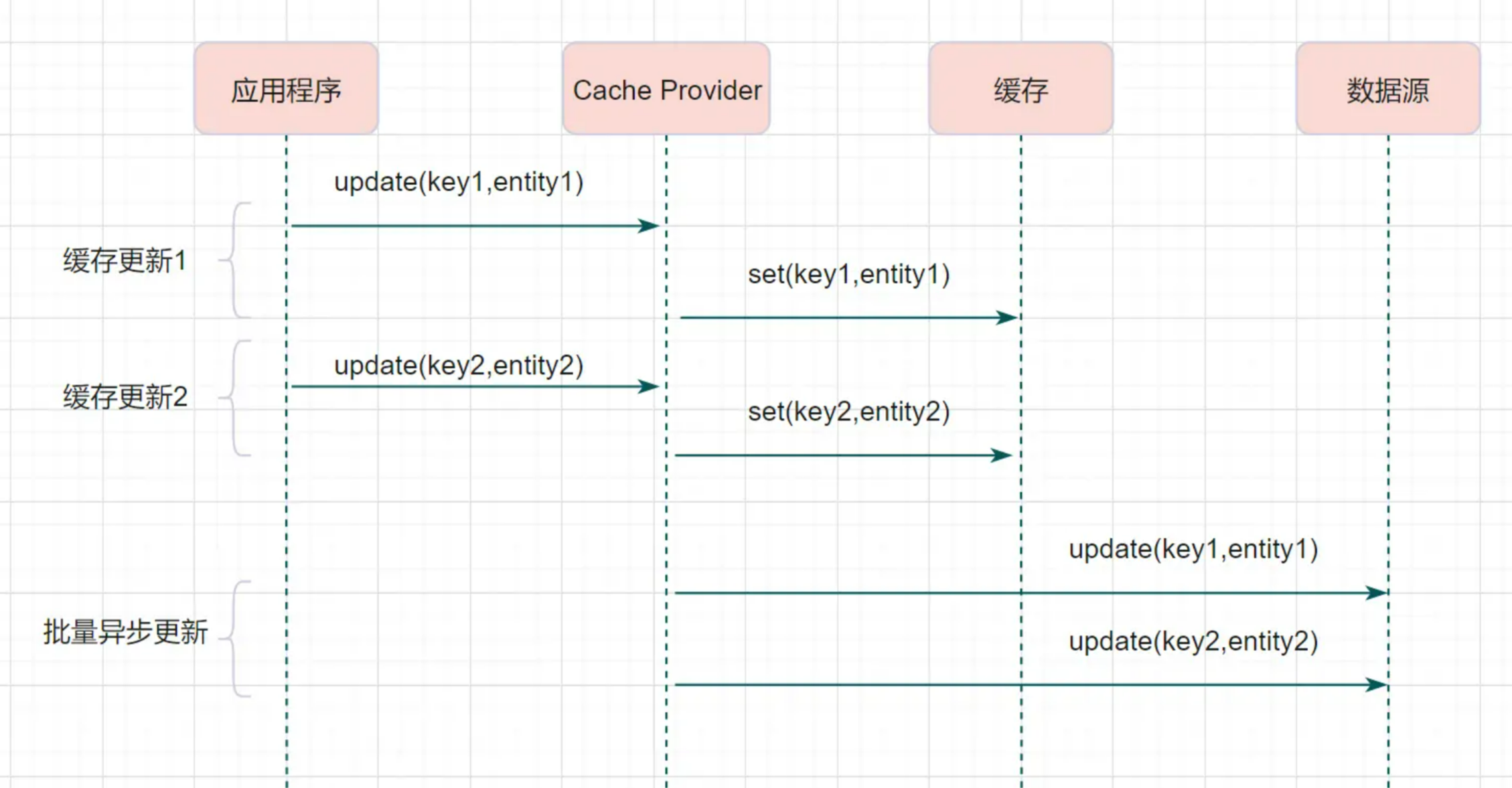
这种方式下,缓存和数据库的一致性不强,对一致性要求高的系统要谨慎使用。但是它适合频繁写的场景,MySQL的InnoDB Buffer Pool机制就使用到这种模式。
操作缓存的时候,删除缓存呢,还是更新缓存?
一般业务场景,我们使用的就是Cache-Aside模式。 有些小伙伴可能会问, Cache-Aside在写入请求的时候,为什么是删除缓存而不是更新缓存呢?

我们在操作缓存的时候,到底应该删除缓存还是更新缓存呢?我们先来看个例子:
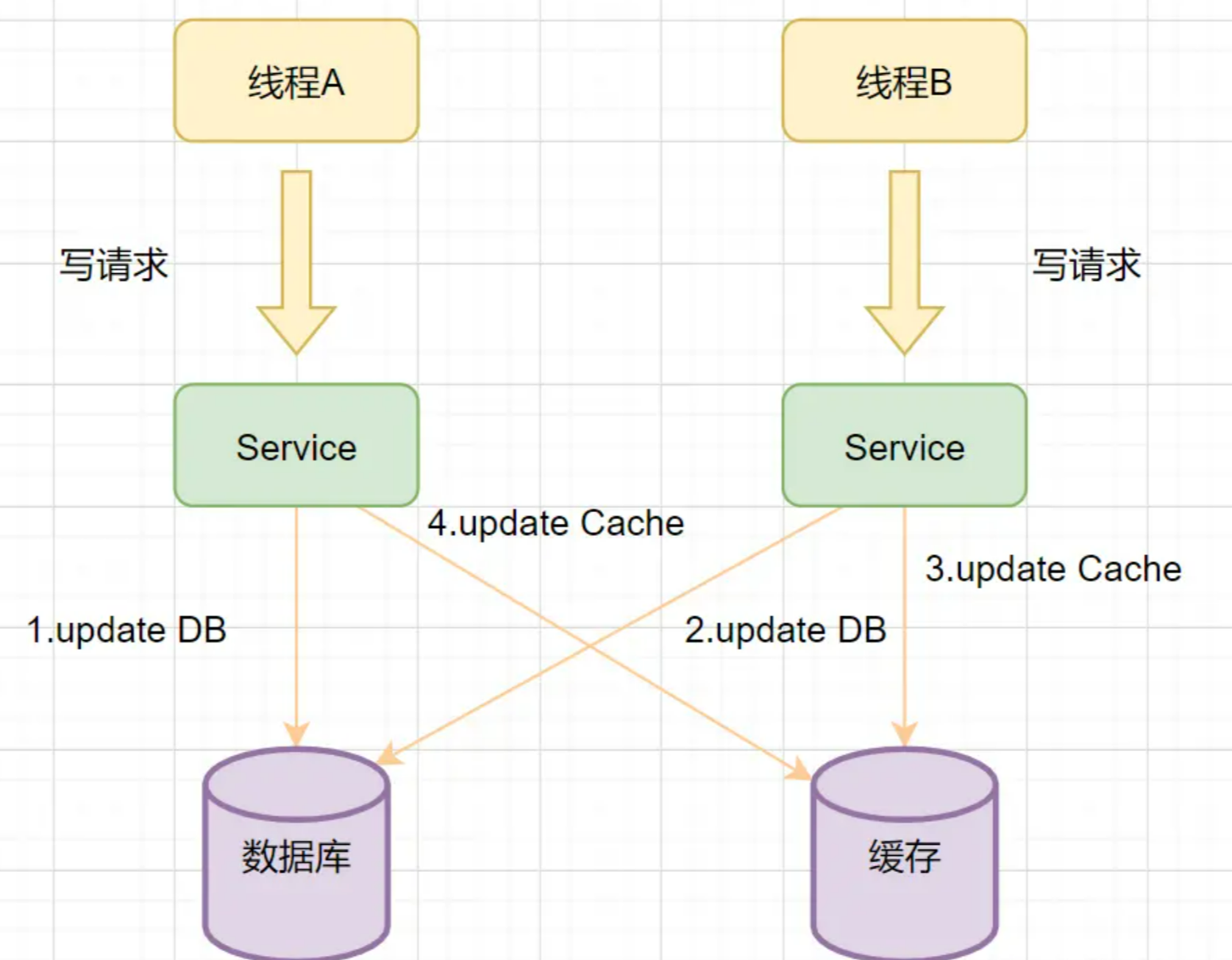
线程A先发起一个写操作,第一步先更新数据库
线程B再发起一个写操作,第二步更新了数据库
由于网络等原因,线程B先更新了缓存
线程A更新缓存。
这时候,缓存保存的是A的数据(老数据),数据库保存的是B的数据(新数据),数据不一致了,脏数据出现啦。如果是删除缓存取代更新缓存则不会出现这个脏数据问题。
更新缓存相对于删除缓存,还有两点劣势:
如果你写入的缓存值,是经过复杂计算才得到的话。更新缓存频率高的话,就浪费性能啦。
在写数据库场景多,读数据场景少的情况下,数据很多时候还没被读取到,又被更新了,这也浪费了性能呢(实际上,写多的场景,用缓存也不是很划算了)
双写的情况下,先操作数据库还是先操作缓存?
Cache-Aside缓存模式中,有些小伙伴还是有疑问,在写入请求的时候,为什么是先操作数据库呢?为什么不先操作缓存呢?
假设有A、B两个请求,请求A做更新操作,请求B做查询读取操作。
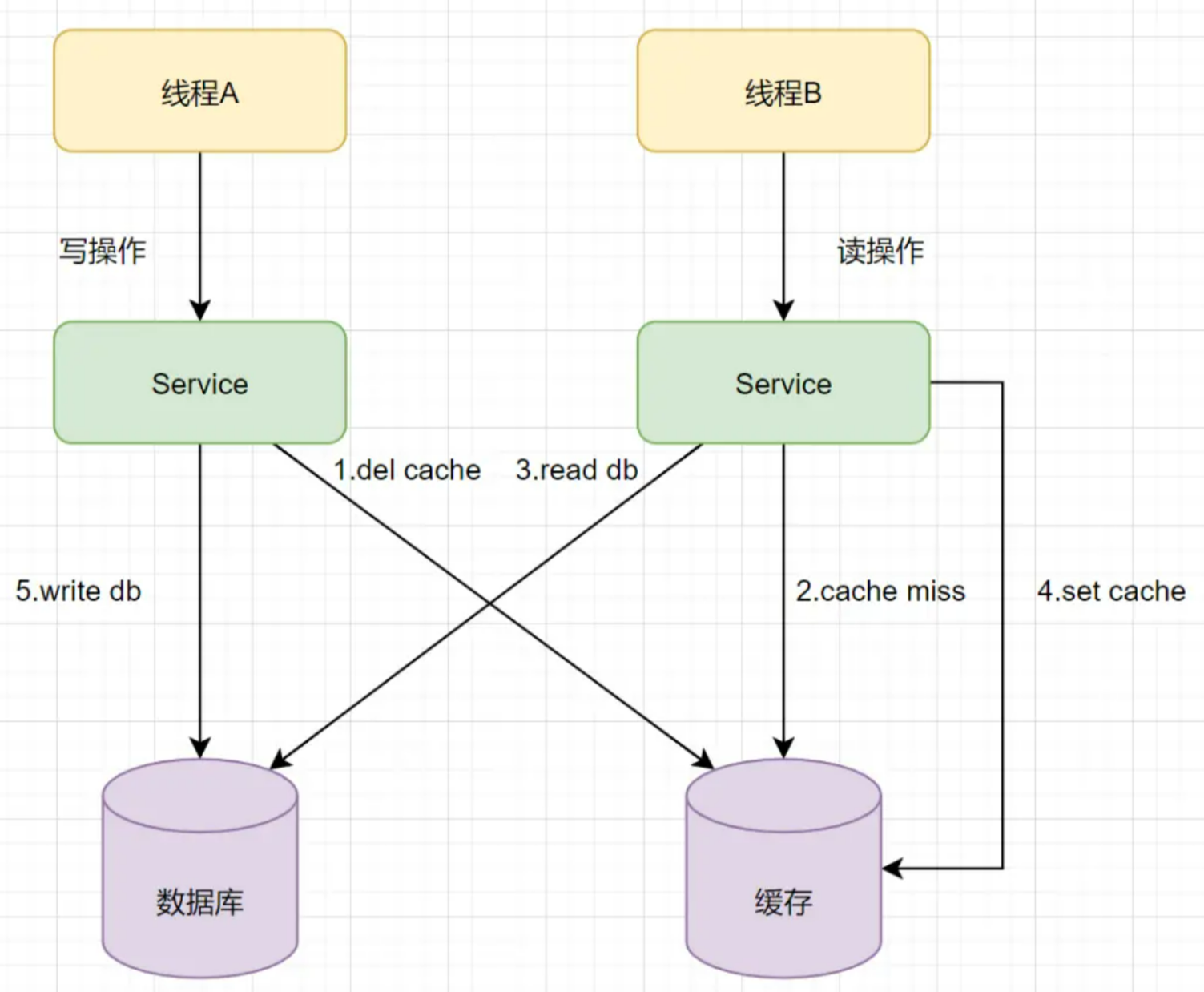
线程A发起一个写操作,第一步del cache
此时线程B发起一个读操作,cache miss
线程B继续读DB,读出来一个老数据
然后线程B把老数据设置入cache
线程A写入DB最新的数据
酱紫就有问题啦,缓存和数据库的数据不一致了。缓存保存的是老数据,数据库保存的是新数据。因此,Cache-Aside缓存模式,选择了先操作数据库而不是先操作缓存。
缓存延时双删
有些小伙伴可能会说,不一定要先操作数据库呀,采用缓存延时双删策略就好啦?什么是延时双删呢?
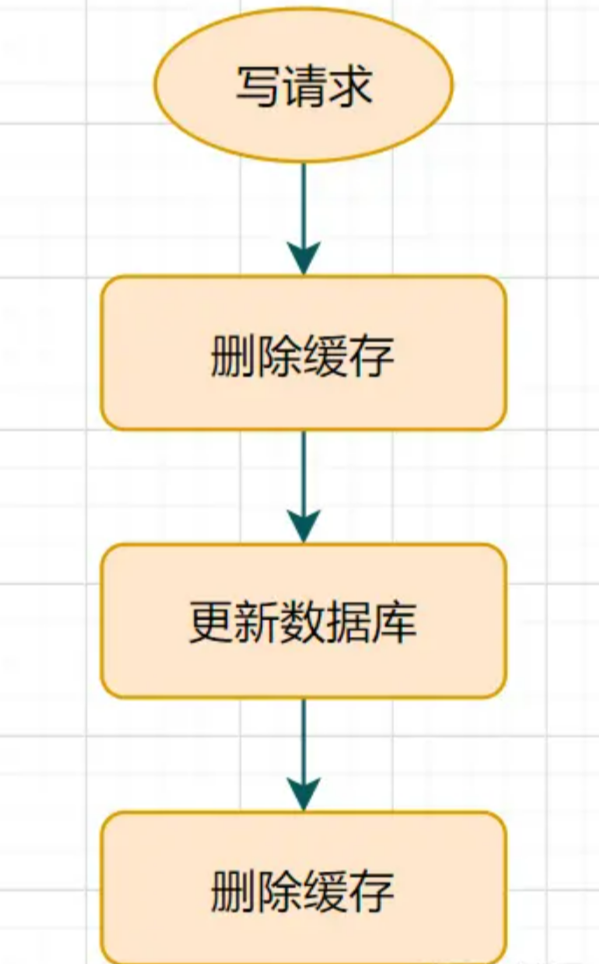
先删除缓存
再更新数据库
休眠一会(比如1秒),再次删除缓存。
这个休眠一会,一般多久呢?都是1秒?
这个休眠时间 = 读业务逻辑数据的耗时 + 几百毫秒。 为了确保读请求结束,写请求可以删除读请求可能带来的缓存脏数据。
删除缓存重试机制
不管是延时双删还是Cache-Aside的先操作数据库再删除缓存,如果第二步的删除缓存失败呢,删除失败会导致脏数据哦~
删除失败就多删除几次呀,保证删除缓存成功呀~ 所以可以引入删除缓存重试机制
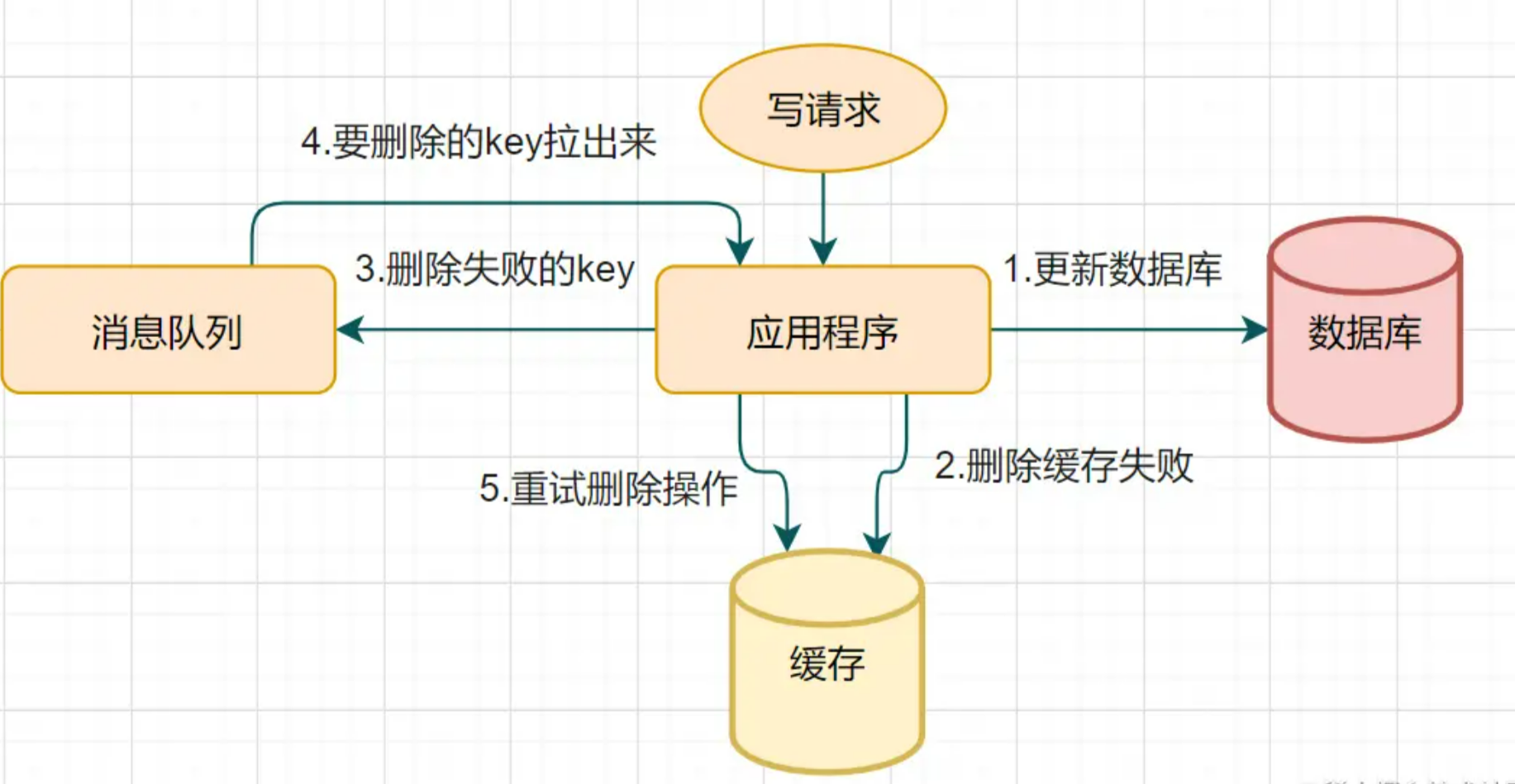
写请求更新数据库
缓存因为某些原因,删除失败
把删除失败的key放到消息队列
消费消息队列的消息,获取要删除的key
重试删除缓存操作
读取biglog异步删除缓存
重试删除缓存机制还可以,就是会造成好多业务代码入侵。其实,还可以通过数据库的binlog来异步淘汰key。
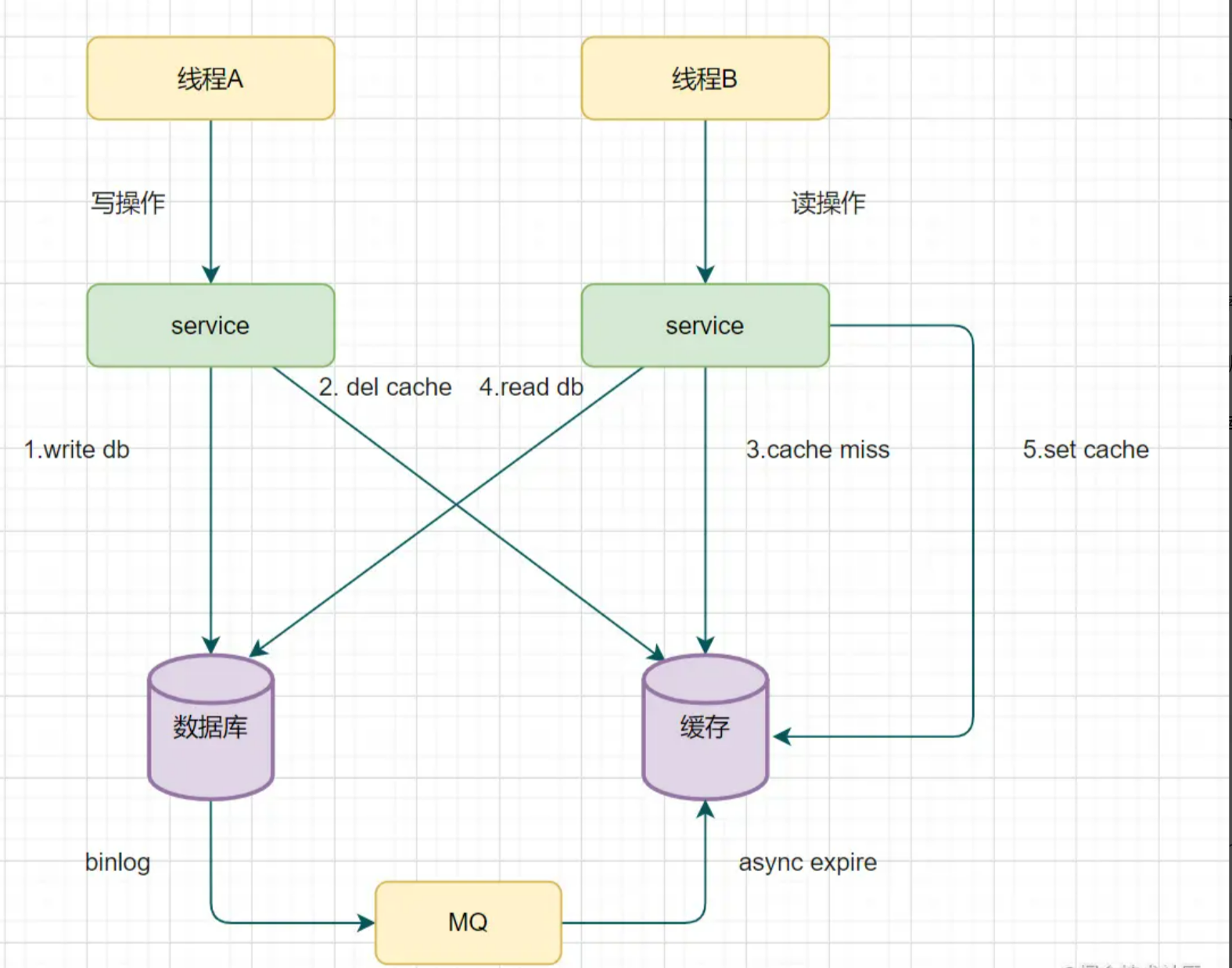 以mysql为例 可以使用阿里的canal将binlog日志采集发送到MQ队列里面,然后通过ACK机制确认处理这条更新消息,删除缓存,保证数据缓存一致性
以mysql为例 可以使用阿里的canal将binlog日志采集发送到MQ队列里面,然后通过ACK机制确认处理这条更新消息,删除缓存,保证数据缓存一致性




不错,很全面